Adottimo Opened AdAcademy.co.uk
For quite a long time we have been whining about the support Google provides for Adsense users. As some of you may know our performance-only contracts are only available to website owners (app or other web property) with 1M page views per month and above, so we wanted to make something that gathered to the needs of smaller websites and starting publishers.
So we created AdAcademy.co.uk
![]()
The AdAcademy.co.uk is a member-based website/platform that provides the knowledge and the learning experience to make working with Adsense and other similar platforms easier. Our team is finally the go-to if you have issues with your online blog or online magazine or other content website monetized through AdSense.
We called it AdAcademy.co.uk because we look forward to launching certifications and qualifications to expand our network of professionals starting from those that have learned from us.
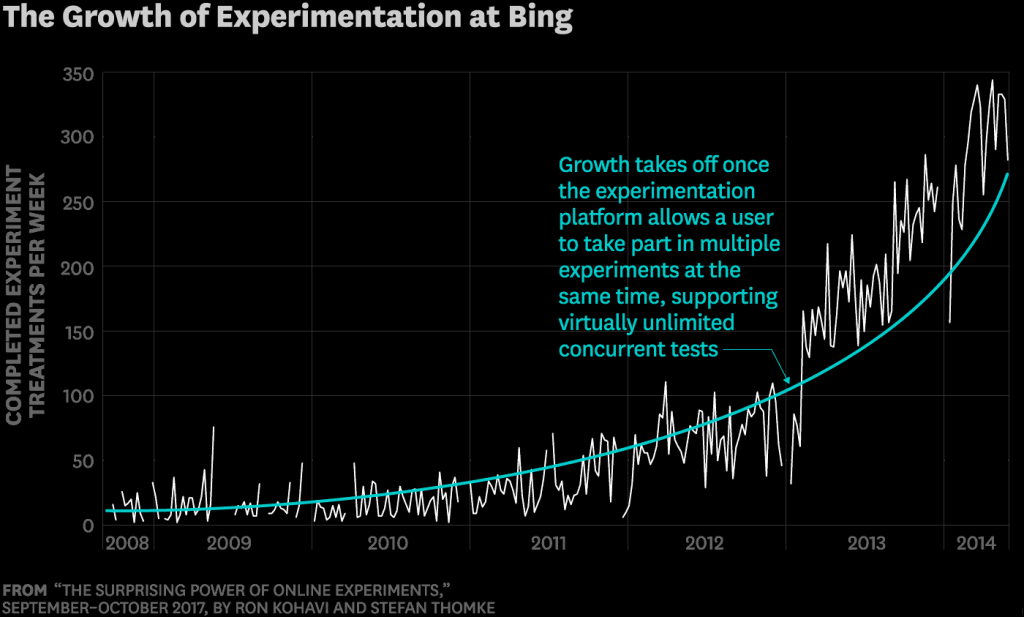
Not long ago we celebrated one of our client making the mark of $500,000 earned in under 6 months staring an Adsense account from $0 (see our Instagram.com/adottimo) and we took the decision that a lot more people could learn.
We don’t need to say that we do not sell any get rich quick formulas just knowledge and experience built in years of hard work that has enabled us and our clients to earn significant financial returns.
So to sum up these are some of the things we will be teaching inside AdAcademy.co.uk :
- Adsense Basics because after reviewing all of the official videos from Google Adsense we found there were more than a few inaccuracies and some gross mistakes or confusing elements
- The truth about DFPs and how to use it
- How to use mobile ads vs responsive ads
- How to increase coverage
- How to chose profitable niches
- How to multiply pageviews
- How to increase CPC (where possible)
- How to increase Page RPM (where possible)
- How to retain users and increase the quality of the ads on your site (which also means increasing profitability)
- The importance of page speed and speed optimisation vs not harming Ad coverage
- How to read the data from Adsense correctly and take decisions
- What to trust in the suggestions of Google Adsense and what not
- How to manage multiple Adservers (Adsesne + others)
- The importance of header bidding
- The importance and how to monitor and improve Active view viewable in AdSense
- The difference between coverage and fill rate (Which Google calls Coverage and Ad Coverage)
- How not to get your Adsense account suspended
- Policy violation prevention
- Really understanding of the key concepts inside the Google Adsense policy (T&Cs)
- And many many other things
Go to AdAcademy.co.uk and let us know if you like this new site